Dzisiaj
jest: 2026-07-15
Aktualizacja dnia: 2026-07-14 19:25:42
7.
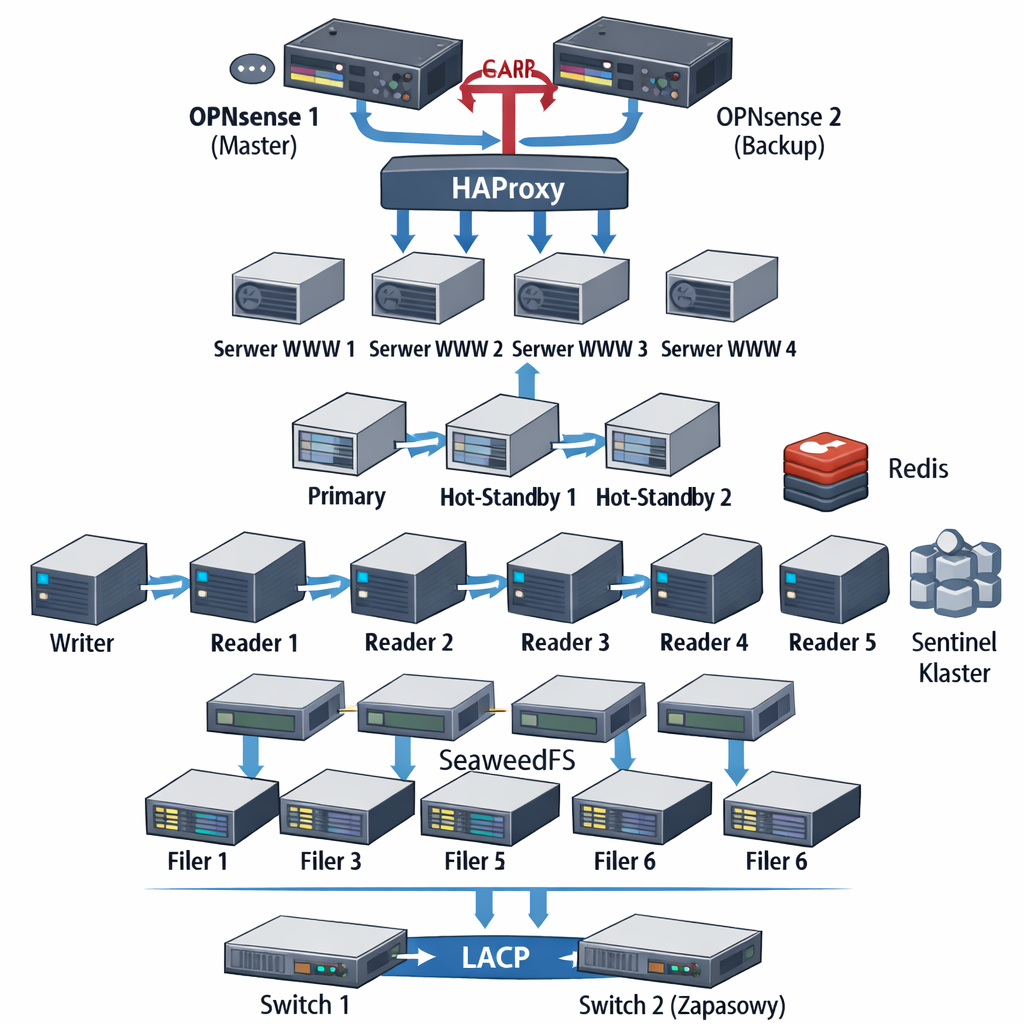
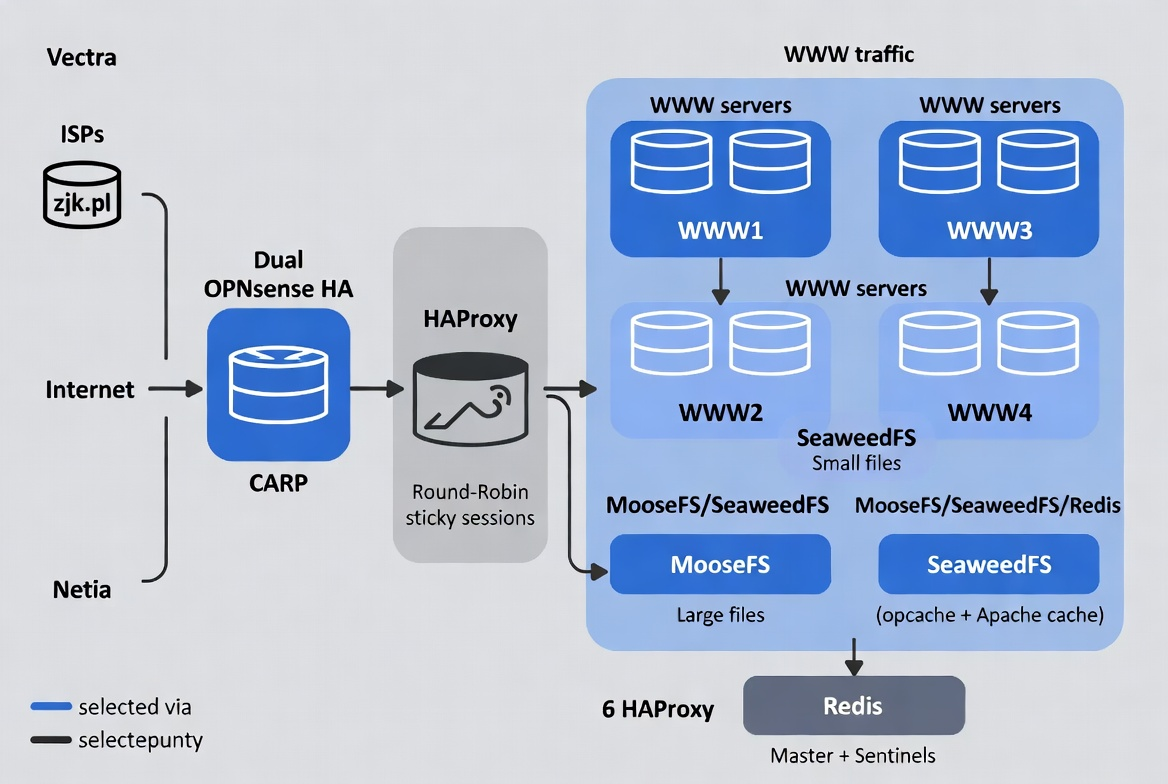
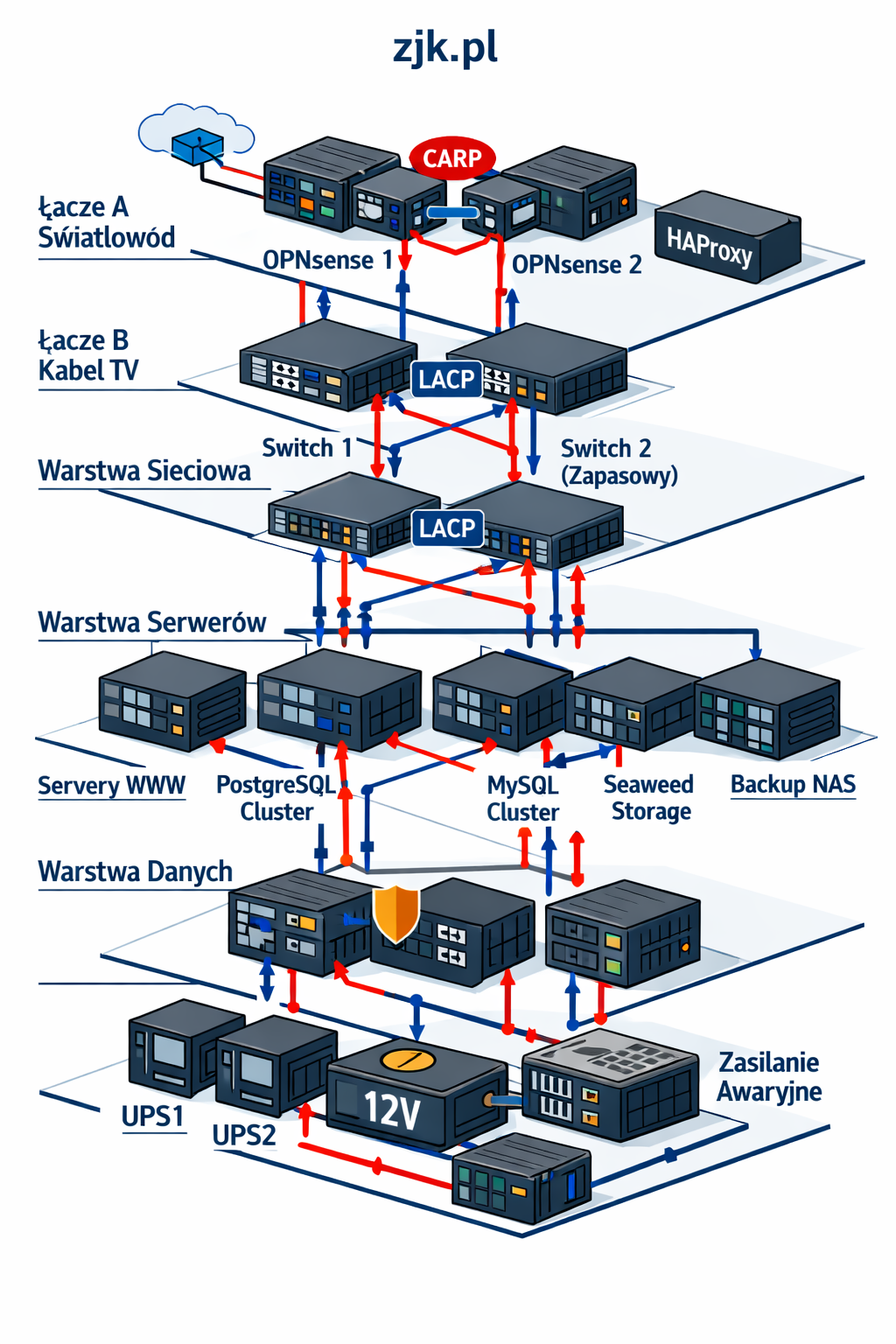
Ilustracje pracy
serwerów
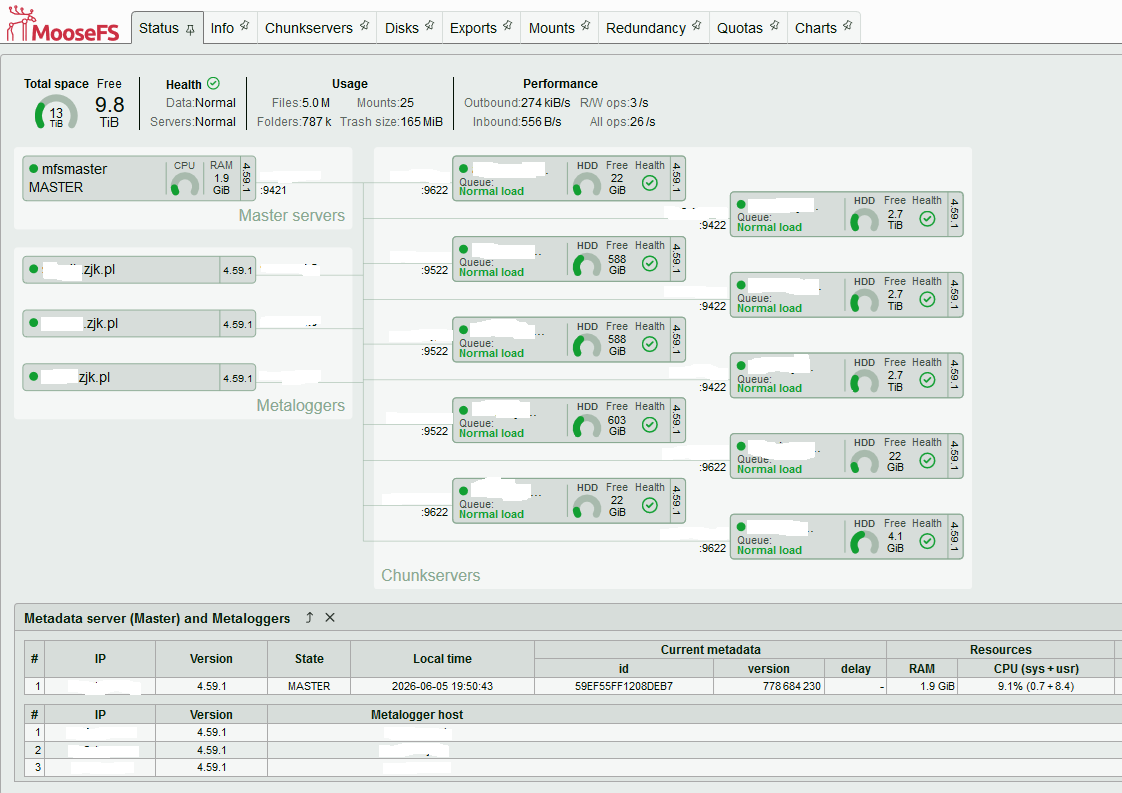
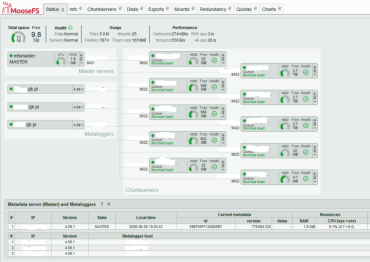
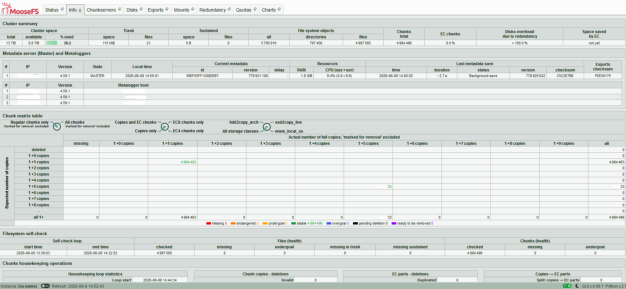
| MooseFS
status 1 |
MooseFS
status 2 |
 |
 |
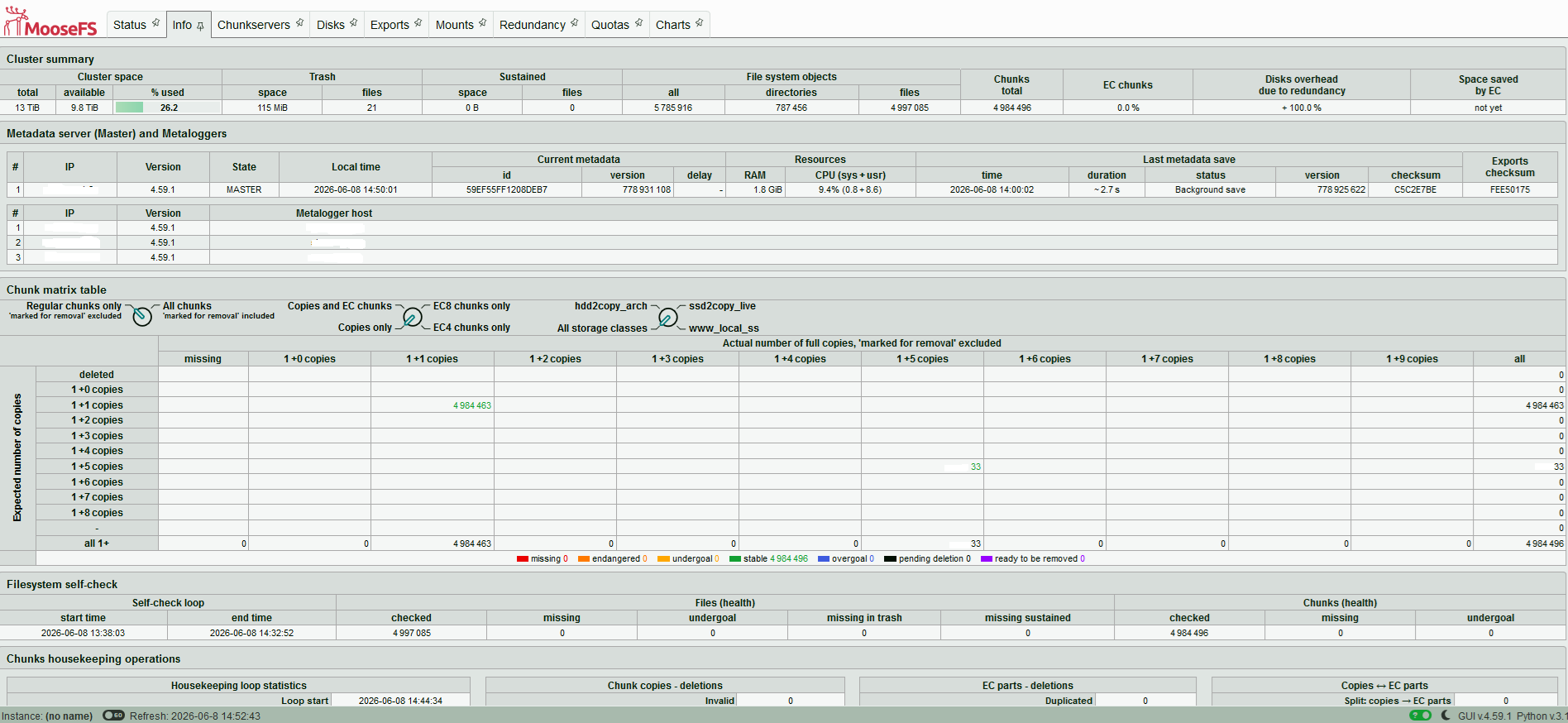
| MooseFS
status 3 |
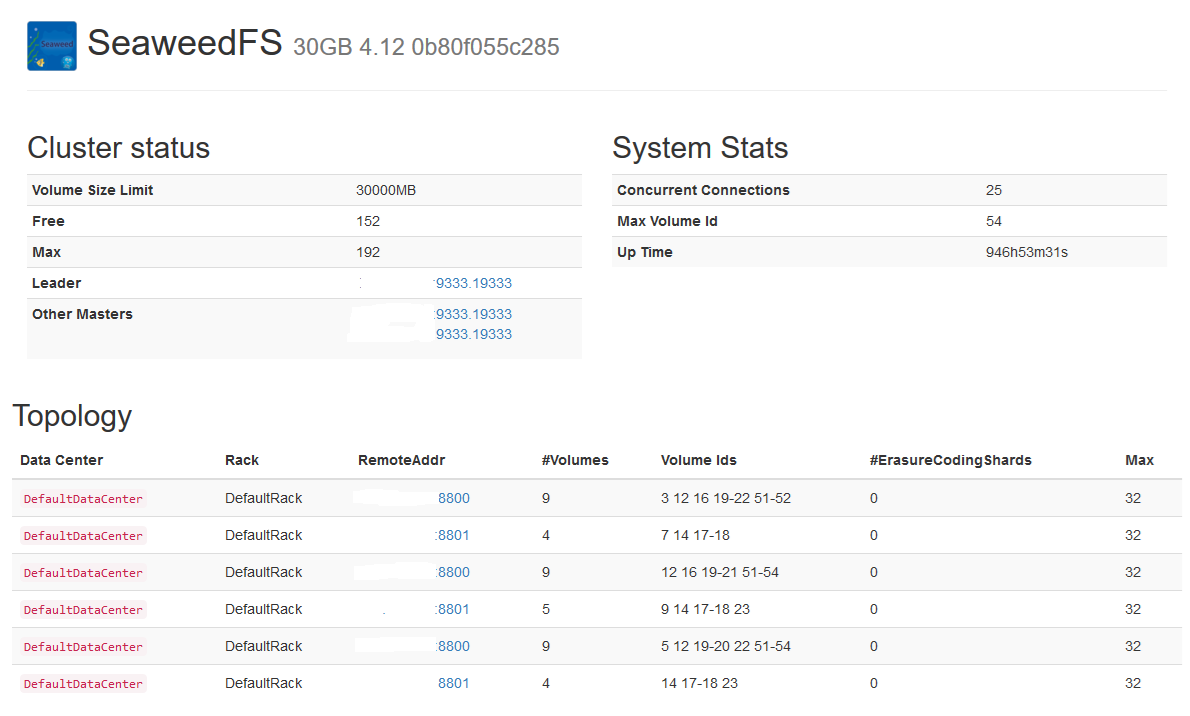
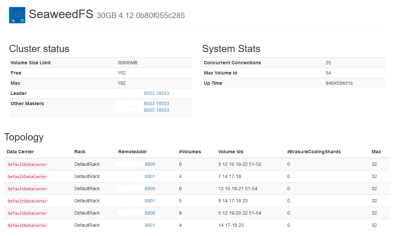
SeaweedFS
status 1 |
 |
 |
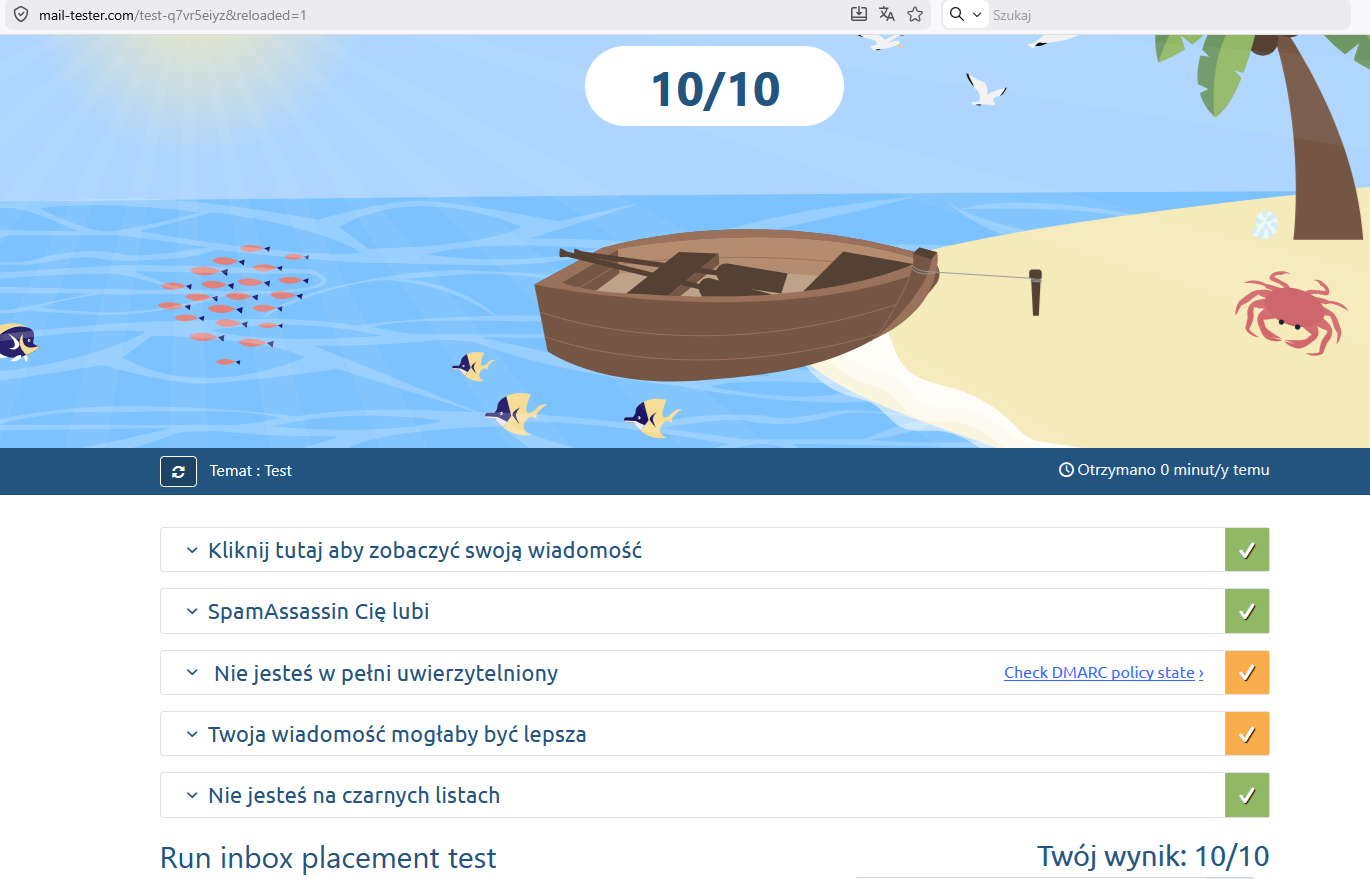
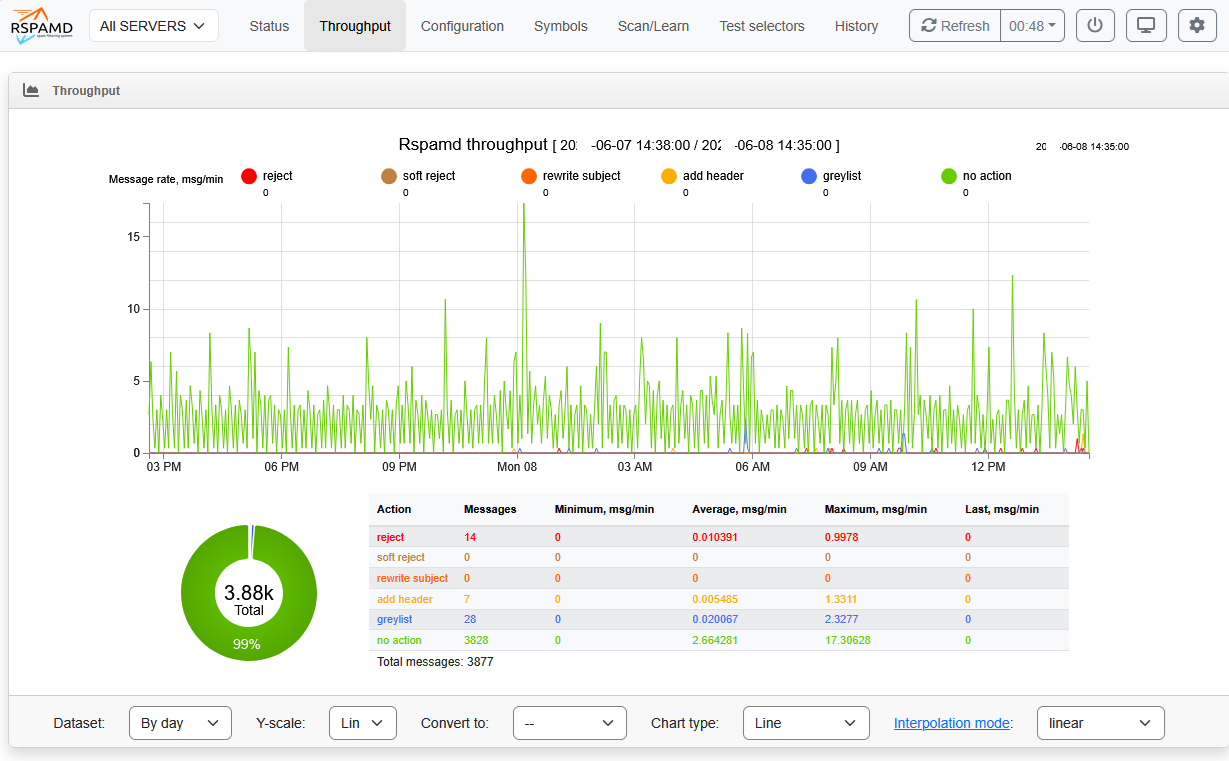
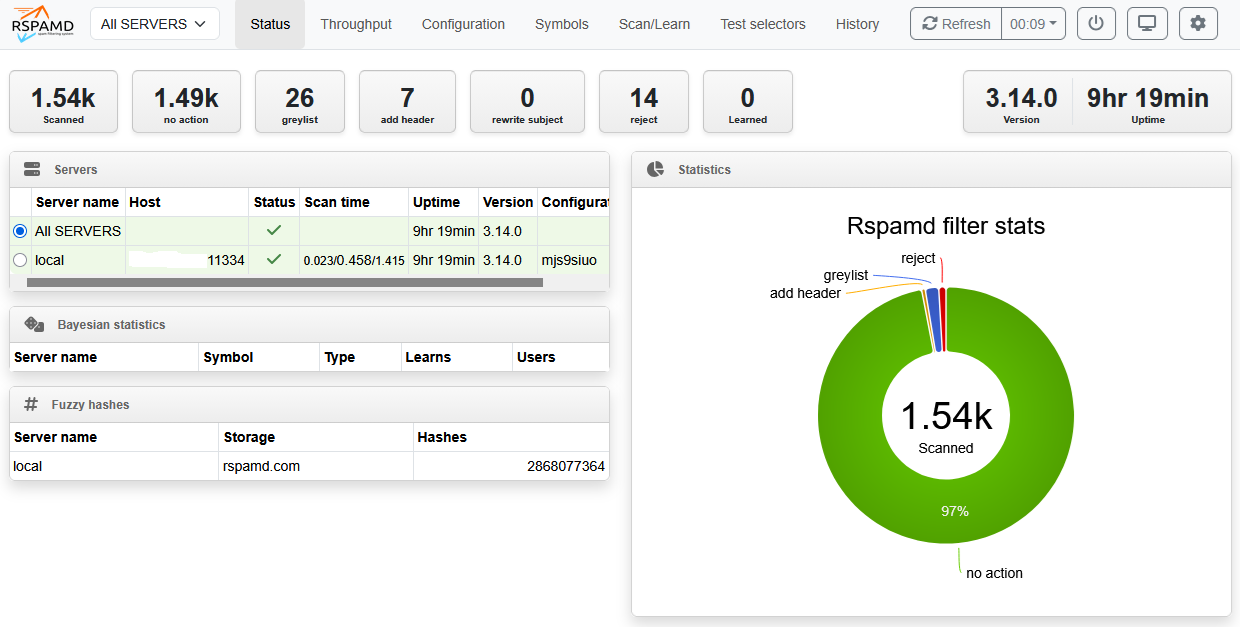
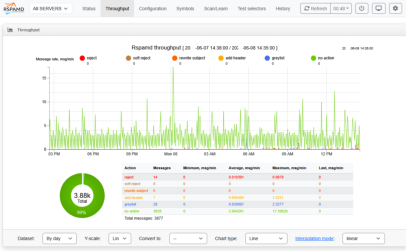
| Rspamd
raport 1 |
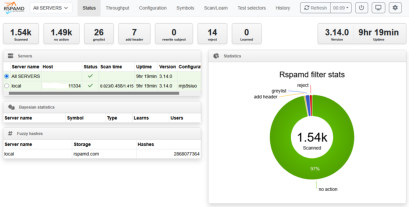
Rspamd
raport 2 |
 |
 |
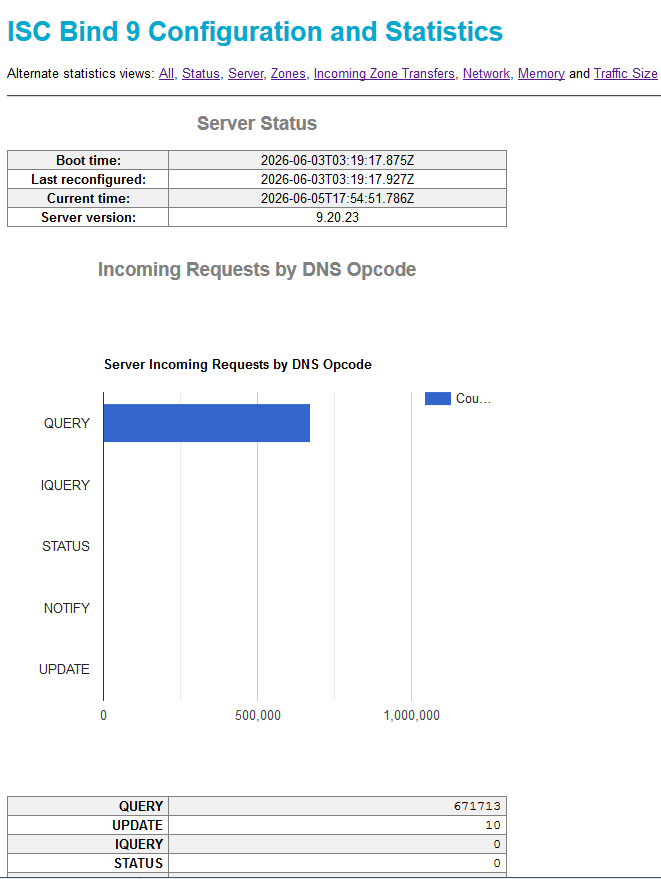
| Bind
raport |
|
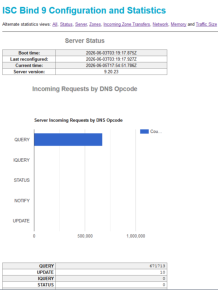 |
|
|
|
Odpowiedzi na ogólne i szczegółowe pytania zawiązane z prowadzeniem serwerów
Patrz [podstrona]
9. Studium
przypadków
Ciekawe problemy - kilka przykładów wziętych z życia, z moich
prawdziwych "przygód" z utrzymaniem serwerowni -
jako studia przypadku.
Patrz [podstrona]
Nieliczne, z dużym trudem
wymienię
kilka, jakie wystąpiły przez 25 lat (stan na 2026 r.):
-
Głównie dyski, może 4-5 w sumie (ważna jest liczba
ogólny dysków, aktualnie to kolo 30 - 35) -
nazw firm produkujących dyski specjalnie nie wymienię, ale
jest pewna
prawidłowość.
- Jedna
karta PCI-E dysków.
-
Kilkanaście wentylatorów, zwykle padają 4x4 cm,
ale także kilka do procesorów (5 może 7), jeden
duży 25 cm.
- Dwa
zasilacze główne ATX.
-
NIE MIAŁEM awarii płyt głównych, procesorów,
pamięci. Może ma znaczenie, że chłodzenie serwerowni
jest wydajne i
nawet podczas dużych upałów, gdy w pokoju mam 35 C,
serwerownia
na "wydmuchu powietrza" nie generuje więcej niż 40 C.
11. Problemy z oprogramowaniem
Zdarzają się systematycznie, szczególnie przy
aktualizacjach
- zmiany w plikach konfiguracyjnych, czasem nowe
funkcjonalności
wymagające obsługi. FreeBSD pozwala na pracę ze źródłami i
własną ich kompilację, dlatego problemów z tej strony nie
ma
dużo. Natomiast stabilność FreeBSD podczas aktualizacji
jest legendarna
(tylko raz czy dwa sprawiła mi jakieś kłopoty), choć warto
przeczytać
przez jej wykonaniem informacje o nowym wydaniu.
Największe
wyzwanie to dotrzymanie kroku najnowszym trendom i standardom. Czytając
te słowa, pamiętajmy, że moje serwery rozpoczęły pracę w czasach, gdy
obowiązywały zupełnie inne standardy – dla przykładu dawniej
strony nazywały się http://www.zjk.pl, dziś oczekujemy https://zjk.pl
(sama zmiana dotyczy nie tylko nazwy, ale stosowania konkretnych
technologii). Niektórych współczesnych standardów
bezpieczeństwa nie da się wdrożyć bez istotnych kompromisów w
przypadku serwisów rozwijanych od wielu lat i opartych na
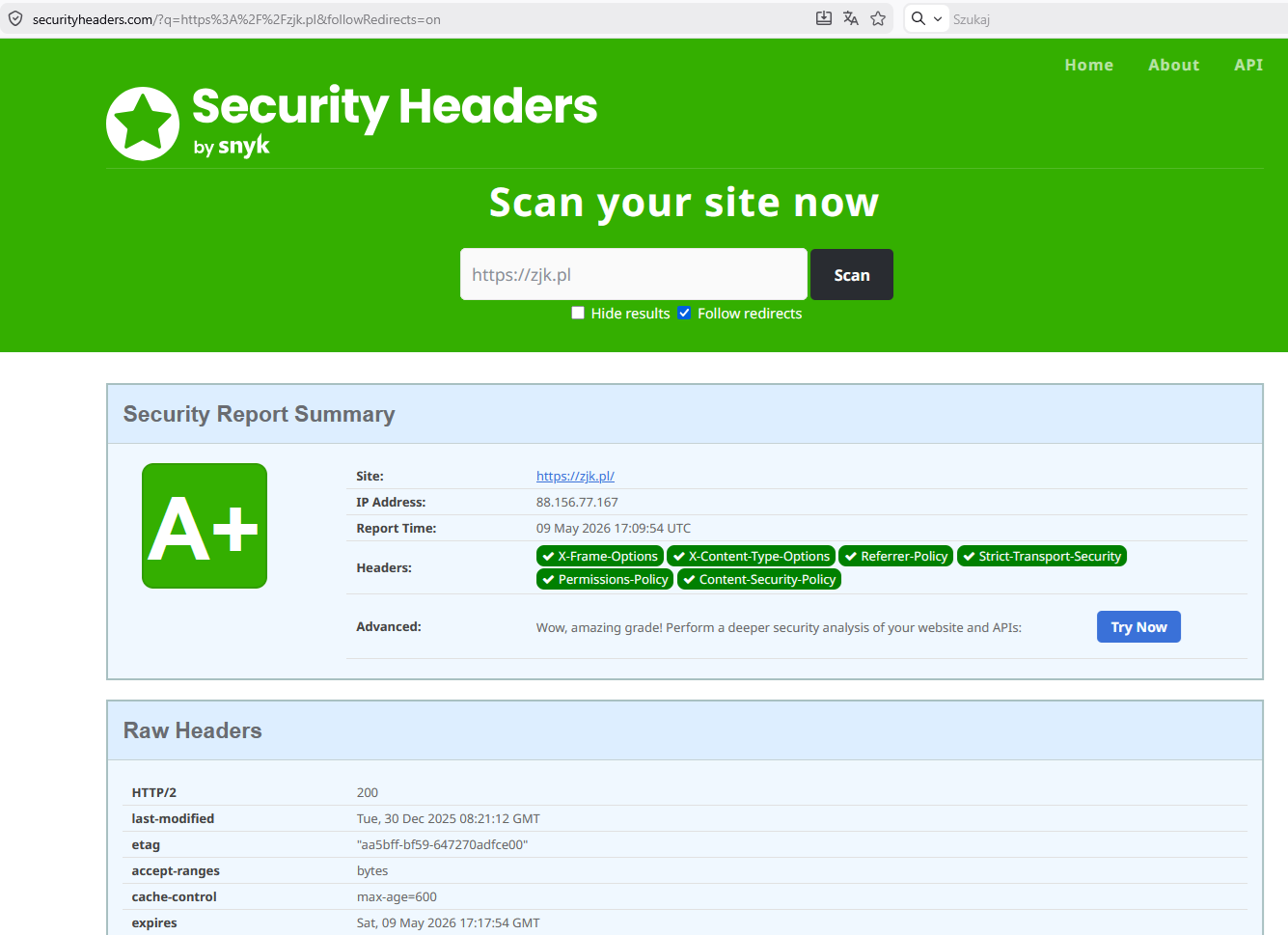
klasycznych technologiach HTML. Przykładem są polityki Content Security
Policy (CSP). Można skonfigurować je niezwykle restrykcyjnie, jednak w
przypadku starszych serwisów opartych na klasycznym HTML,
własnych skryptach czy nietypowych rozwiązaniach często prowadziłoby to
do blokowania części treści lub funkcji strony. Ta z zablokowanym CSS i
pobieraniem obrazków całkowicie utraciłaby wygląd po włączeniu
najnowszych nagłówków – super bezpiecznych, ale
blokujących typowe metody budowania takich stron. O ile niewielkie
skrypty JavaScript można jeszcze objąć dodatkowymi ograniczeniami
bezpieczeństwa, o tyle pełna zgodność ze współczesnymi, bardzo
restrykcyjnymi politykami CSS i CSP wymagałaby daleko idących zmian w
strukturze strony. Wprowadzenie pełnej zgodności ze
współczesnym, bezpiecznym CSS jest praktycznie bardzo
trudne – trzeba sięgać do dużych kompromisów między
bezpieczeństwem, dobrymi ocenami strony a jej skutecznym
funkcjonowaniem. Jest nawet problem z obrazkami, bo starsze (ale nie
stare) edytory HTML już nie czytają np. formatu WebP. Oczywiście można
wskazać duże serwisy, które spełniają wiele nowych
standardów bezpieczeństwa. W praktyce jednak sytuacja nie zawsze
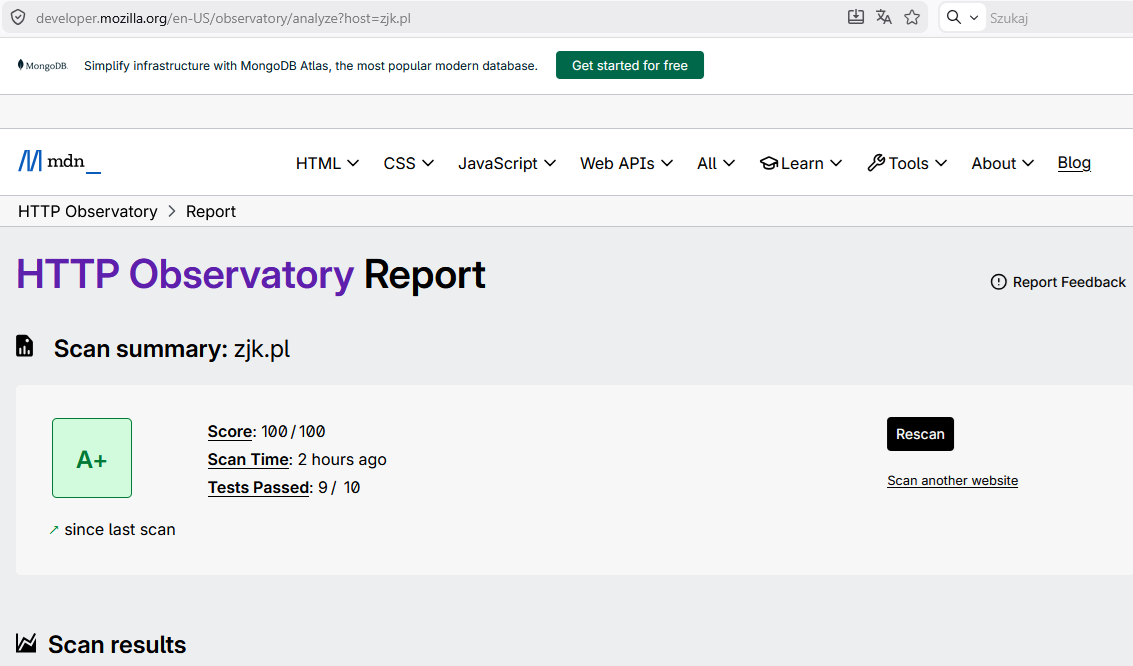
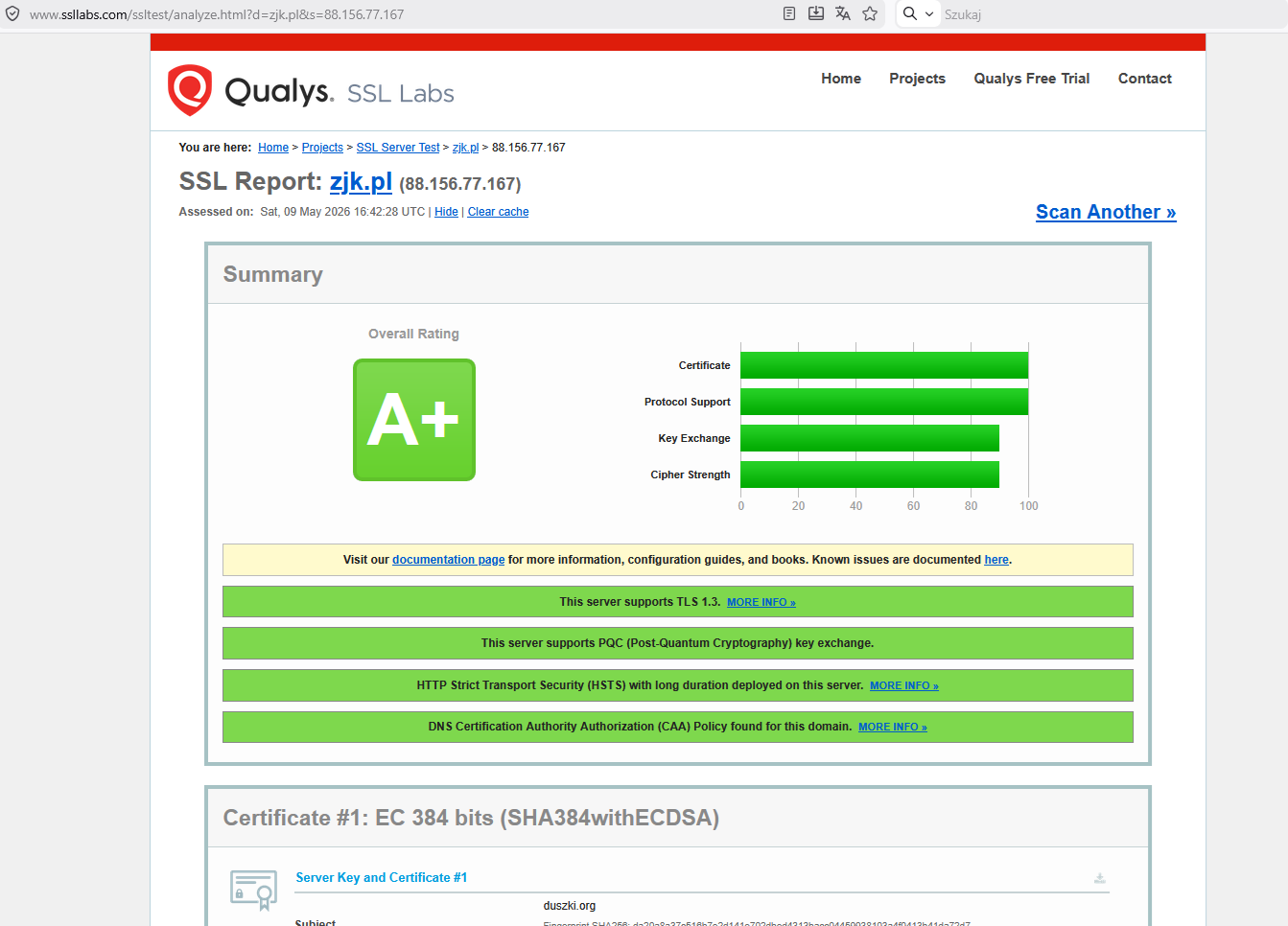
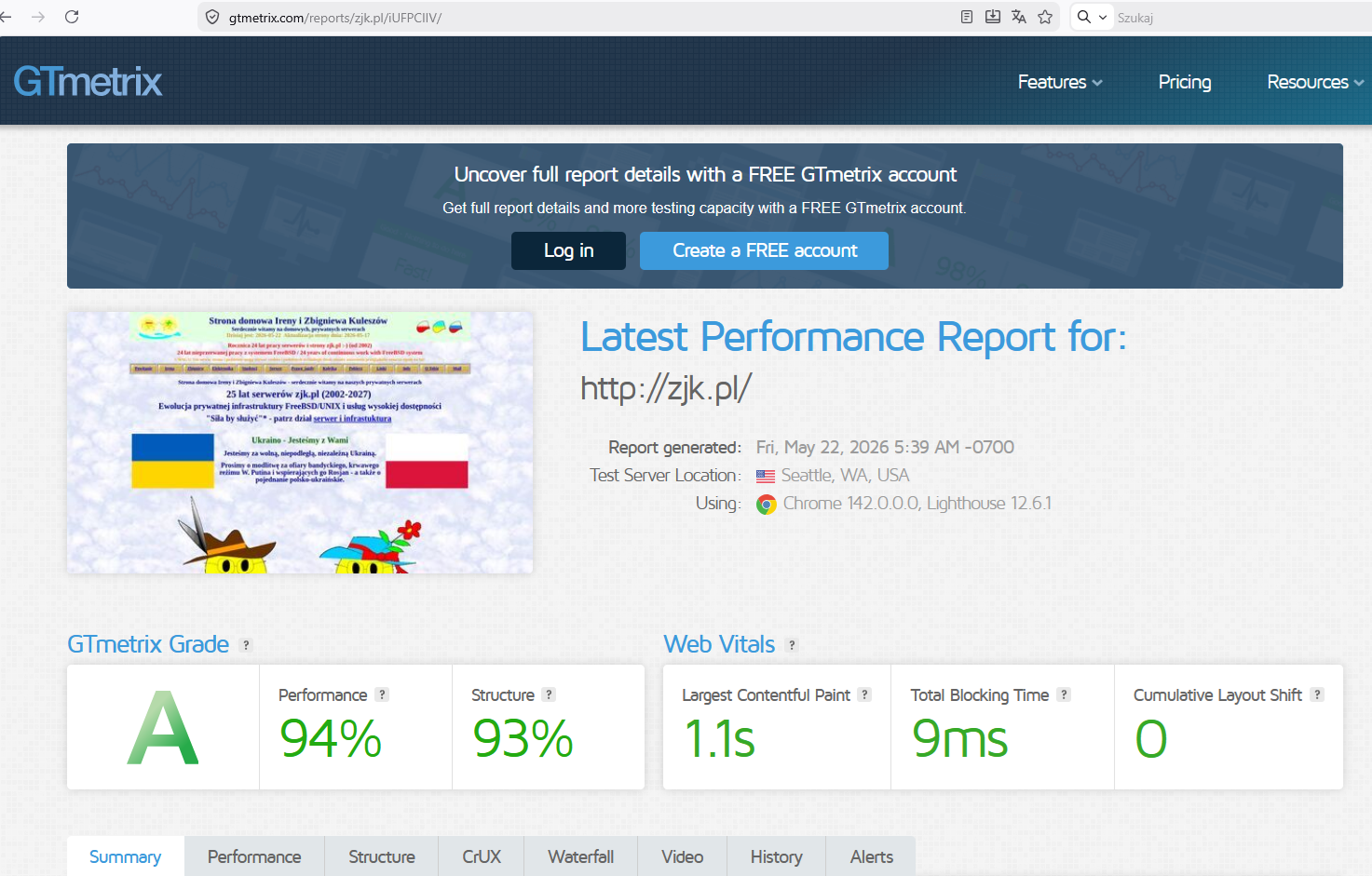
wygląda tak idealnie, jak mogłoby się wydawać. Przed chwilą uruchomiłem
skaner centralcsp.com na wielkim, znanym polskim serwisie i wynik to
5/100, drugi serwis 6/100, moje wyniki w okolicach od 5/100 do 8/100
(zmniejszyłem świadomie wynik, żeby nie blokować treści na mojej
stronie) – czyli zjk.pl wcale nie sprawia wrażenia zacofania.
:)
To pokazuje, że w codziennej praktyce administratora
trzeba po prostu szukać zdrowego balansu. Czasem świadomie rezygnuję z
technicznych nowinek, bo produkcyjne systemy mają przede wszystkim
stabilnie działać i służyć ludziom, a nie tylko idealnie pasować do
teoretycznych wytycznych automatycznych skanerów. Ostatecznie
sieć to sztuka kompromisu. Zamiast ślepo gonić za idealnym wynikiem w
testach bezpieczeństwa, wolę skupić się na tym, by serwer po prostu
skutecznie i niezawodnie dostarczał treść. Teoria to jedno, a stabilnie
działająca od lat strona – drugie. Dlatego ostatecznie wybieram
po prostu pragmatyzm. Świadomie rezygnuję z niektórych
rygorystycznych technologii, bo żywy organizm, jakim jest serwer, musi
przede wszystkim bezproblemowo działać w realnym świecie.
14.
Różne informacje o serwerach
na podstronach
UWAGA -
tłumaczenie strony w toku: